AdaBoost for beginners
Boosting is an ensemble model in which weak learners are connected sequentially. Each weak learner is expected to correct the mistakes of its previous learner. This makes each of the model concentrate on the misclassified samples and the overall model achieves less bias than its individuals.

AdaBoost Algorithm is also known as Adaptive Boosting is an Ensemble modelling technique used in Machine Learning. The idea of Adaboost goes as, we start with a base model which has equal weight given to all its samples. The model can predict according to its capacity. In the next step, misclassified samples are given more weightage in order to draw better attention of the next weak learner. We finally will have a series of models which predicts each of the samples on their own. Then the model is rated or weighted according to its performance. Less weightage is given to the model that makes more incorrect predictions and higher weightage is given to the model that makes more correct predictions. In other words, the importance given to each of the models depends on their total error.
Algorithm:
To understand how Adaboost works, let us consider a sample data set as follows:
Data belongs to heart attack analysis from Kaggle. Output 0 indicates a prediction as ‘Risk is low’ and Output 1 indicates a prediction as ‘Risk is high’.
Step 1: Predict
There are 10 samples in the data and for the base model, we consider an equal weightage to all the samples which is 1/n.

Now the base model makes its predictions according to its capacity and let us consider that the prediction is as follows:

There are certain misclassified samples made by this weak learner in this step.
Note: A weak learner is any model that is definitely better than a random guess. Hence it must be able to predict well for more than half of the samples.
Step 2: Calculate Model Weightage
Importance given to a model is denoted by α and it is calculated as α = 0.5ln((1-TotalError)/TotalError). The value of total error always lies between 0 and 1. Hence the value of α can be correlated as follows:

Ø When the individual model performs well: It has a low error rate. Then α is a large positive value and the model has a high importance in the final model.
Ø When the individual model is unsure: It has an error rate of 0.5. Then α is 0 and the model has no say in the final model.
Ø When the individual model performs poor: It has a high error rate. Then α is a large negative value and the model is considered least significant in the final model.
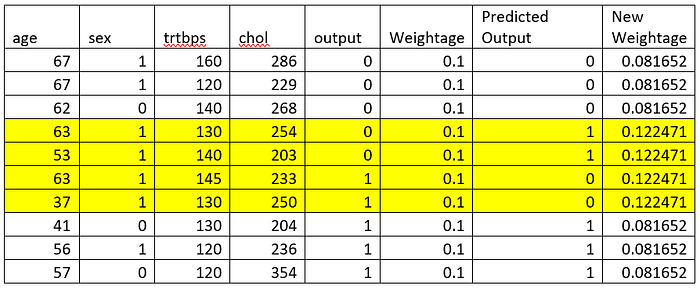
Here in the example data, there are 4 misclassified data samples. Hence the total error is 0.4.
α is calculated as 0.5*ln((1–0.2)/0.2) which is 0.2027
Step 3: Calculate Individual Sample Weight
Let us calculate new weights for individual samples.
New sample weight for incorrectly classified sample = original sample weight * e^ α
New sample weight for correctly classified sample = original sample weight * e^- α
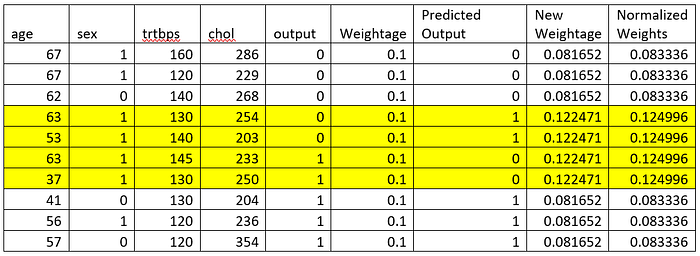
Step 4: Calculate Normalized New weights
It is important to normalize the new weights in order to proceed further. Normalization goes as
Normalized weight = P(xi)/ ∑P(xi)
Now let us put the new weights across a roulette table.

Now when we turn the table, the probability of the pointer stopping in a higher area pie is more.
In the same way, let us replicate the data set to have the higher weighted samples to multiply accordingly. Now the new data set tends to have multiple copies of the misclassified samples.

Step 5: Repeat the above steps with the newly computed dataset while training the next model in the ensemble.
Finally, the Adaboost model makes predictions by having each of its model classify the sample. Then we split the models according to their decisions. We add up the significances of each of the models in their group. The decision made by a group which has the largest significance sum is taken as the final prediction for the sample.